Software projects produce artifacts—a concept less particular than package which has a version, manifest and structure conforming to some package system. Package systems are smart, and thus complex. The key feature of an artifact is that it is dumb.
Package management is a hard problem, with lots of half-broken systems serving particular ecosystems: Cargo for Rust, pip for Python, NPM for node.js, Maven for Java. Artifact systems are not so well-studied, though the concept is high-leverage: unlike package systems, an artifact system can:
- store arbitrary artifacts, like a filesystem (Python
pipserves only Python packages) - serve arbitrary consumers (Python
piprequires Python on the client) - provide a trivial interface, so any client can push or pull artifacts in a predictable manner
- sidestep ambiguous version-resolution problems, by mapping artifacts to DVCS hashes
To design a system there are two options:
- Rockstar solution:
- Develop a web service with an API, fix bugs, add features, update clients, deprecate features.
- Repeat.
- Simple solution:
- Put artifacts in a flat list of locations which map to DVCS revisions.
- Follow a trivial protocol.
- Run a script at the end of every build.
- No new API, service, or software is needed.
This essay describes the simple solution.
Simple design
Use simple patterns automated by tooling. —Adrian Cockcroft, Netflix
Storing ad-hoc flags in DynamoDB or some other centralized bookkeeper(s) requires immediate and ever-accumulating coordination. Human coordination is expensive because it is tedious, high-latency, and hard to verify.
Adhering to a stable protocol minimizes coordination (non-compliant parties are just ignored); only change requires coordination (cf. adoption of HTTP/2). Trading short-term convenience to avoid long-term coordination is good.
Simple systems are often insufficient; but it turns out that smart systems, also, are often insufficient and difficult to change, maintain, or even use. Simple systems have a tendency to exist and be useful long after the state of the art has surpassed them.
- binary streams are used to connect arbitrary processes
- text files are ever-present and can be read by any computer
Robust simple systems can be used as substrate for more complex systems:
- git-annex and bup are built on git
- git itself is strongly dependent on zlib, SHA, and basic filesystem operations (old, common, “boring” tools)
- go insists on simple concepts and unclever features
- AWS S3 is a global, flat list of buckets with no query support
- RISC, NAND, … nMOS ;)
If you use an infrastructure service like AWS, it is the lingua franca of your
organization: your tools, services, and developers all speak it. boto and S3
are the least-common-denominator of capabilities. A blob on S3 can be fetched
by web browser, curl, or a REST client.
We can use AWS S3 to build a serverless, API-less, decentralized artifact source.
Artifact system overview
The system has four concepts:
- Artifact: A thing produced by a build
- Address: Global location of the artifact for a given build; each address has a parent (and ancestors)
- Metafile: JSON map of artifact names and their addresses
- Metalogic: Script (
build_meta.py) that builds the metafile
Artifacts are stored in S3. All artifacts for all projects (yes, all) live in the same S3 prefix (folder), which contains a flat list of unique ids corresponding to the DVCS revision:
s3://dev/builds/<hash>
^ ^ ^
| | unique id (VCS revision)
| prefix (folder)
bucket
Because a DVCS revision is reasonably unique (SHA), there’s no need for any human to tend to a garden of folders (“this project goes here, that project there…”). It is important that the list is flat: this means that existing tools won’t need updates to understand how to traverse the artifacts, and humans can reason about the system to use and extend it without coordination.
When a commit is pushed to a project, the metalogic immediately puts a “stub” metafile at the artifact address. The stub is the first metafile found in any ancestor. Each address has a parent and ancestors defined by the VCS. (The parent is stored in the metafile so that traversal of the artifact addresses is possible without querying the VCS.)
When a build finishes, it uploads its artifacts and re-runs the metalogic, which re-generates the metafile.
Before a build finishes, the previous artifacts can be used, by inspecting the metafile (which contains a map of artifacts to addresses).
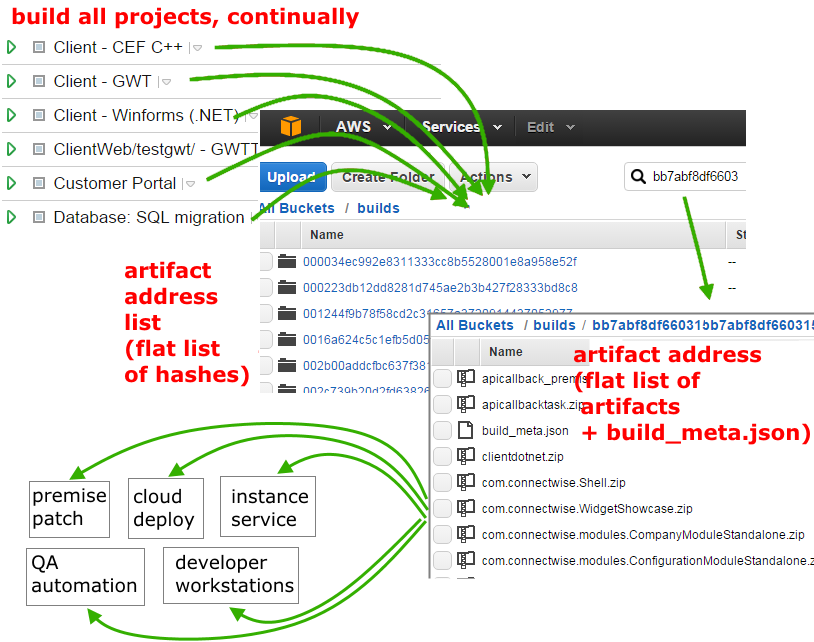
Address
Artifacts for a given DVCS revision (git hash)–for any project–are stored at an artifact address, which is just a snapshot of artifacts corresponding to a DVCS revision. An artifact address has the form:
s3://dev/builds/<hash>
where <hash> is the VCS revision for that project. All projects store their
artifacts in this flat list of addresses.
Artifacts can be retrieved at any time in the future for deployment or inspection.
Metafile: build_meta.json
We defined artifact address as a snapshot of the project output for a given DVCS revision. From that snapshot we should be able to deploy or install the product. But each snapshot may be “sparse”: it contains only artifacts that actually changed, and the missing artifacts are resolved by looking at the ancestor addresses. If a build wasn’t triggered to produce an artifact, we assume that the “nearest” ancestor artifact can be used in its place. Missing artifacts are resolved by following the parent address until all artifacts are found (see Metalogic).
The flattened result of the resolved artifacts is stored in the metafile
build_meta.json. (It’s just JSON, called “the metafile” for brevity.) Here is
the metafile structure:
{
"commit": "<value>",
"parent_commit": "<value>",
"artifacts": {
<name>: <value>,
<name>: <value>,
...
}
}
commitis the current artifact address (VCS revision, identical to the git commit hash).parent_commitis the parent artifact address (parent VCS revision, identical to the git parent commit hash).artifactsis a list of artifact names and their nearest location.
Here’s an actual build_meta.json metafile sample:
{
"commit": "bb7abf8df6603159deacf1e1060c3dbf49489d8a",
"parent_commit": "f60d13d240dff31209eeada1465220c31d4fcb8e",
"artifacts": {
"apicallback_premise.zip": "bb7abf8df6603159deacf1e1060c3dbf49489d8a",
"apicallbacktask.zip": "bb7abf8df6603159deacf1e1060c3dbf49489d8a",
"cef.zip": "4f07cad8358a354511c79f7aa0d652e22810d1da",
"clientdotnet.zip": "bb7abf8df6603159deacf1e1060c3dbf49489d8a",
"outlooksyncworkflow.zip": "4f07cad8358a354511c79f7aa0d652e22810d1da",
...
}
}
In the above sample, the apicallback_premise.zip artifact was built at the
current commit. In contrast, cef.zip is resolved to some ancestor (not the
immediate parent in this case).
Metalogic
The build_meta.py script is called the metalogic, a small (~200 LOC) python
script that generates the build_meta.json metafile.
The metalogic algorithm follows:
- Look for artifacts at the current address. (The Protocol
specifies that build scripts must upload their artifacts to
s3://dev/builds/<hash>each time a build finishes.) - If artifacts are missing, look at the parent.
- Repeat until all artifacts are found, or MAX is reached.
- If artifacts are still missing, look at the parent metafile and merge it
with the current metafile.
- Repeat until the metafile is fully resolved, or MAX is reached.
A key feature of the metalogic is that it must be safe to run at any time (idempotent). Various hooks may run it at any time, without fear of causing some undesired state. The VCS runs the metalogic immediately at every commit, in order to “stub” the metafile immediately so that any dependent system may assume that the metafile for any valid VCS revision always exists (even though its resolved artifacts will be that of its nearest ancestor). Every build runs the metalogic after the build finishes, regardless of whether the build currently produces artifacts or not (because projects change often, and they may start producing artifacts at any time).
Only known artifacts are allowed. To emphasize predictability and reduce ambiguity, the metalogic raises an error (fails the build) if it sees an unknown artifact. This ensures that artifacts are never missed, because the artifacts list is updated immediately to avoid the build error.
Here’s a sample log of the metalogic after a build, resolving missing artifacts by checking the artifacts and metafiles of ancestors:
build_meta.py: missing artifacts at db33904e90b55ab19db84732caaca6a256323d01
apicallbacktask.zip
connectwiseindexer.zip
emailrobotworkflow.zip
nsnclientservice.zip
apicallback_premise.zip
cef.zip
connectwiseindexer_premise.zip
cwwebapp_db.sql
cwwebapp_login_db_premise.bak
emailaudittask.zip
emailrobot_premise.zip
build_meta.py: missing artifacts at 07fc5c649ef2370325749fee09016e4969cd8293
emailrobotworkflow.zip
cwwebapp_db_cloud.bak
cwwebapp_db_premise.bak
emailrobot_premise.zip
reportwriter.zip
build_meta.py: same artifacts missing in 135 ancestors
build_meta.py: missing artifacts at 2175d2b49ac60af36737168c8c3fc39a2db8639a
cwwebapp_db_cloud.bak
cwwebapp_db_premise.bak
build_meta.py: same artifacts missing in 57 ancestors
build_meta.py: resolving missing artifacts via ancestor build_meta.json files
build_meta.py: build metadata:
https://s3.amazonaws.com/dev/builds/db33904e90b55ab19db84732caaca6a256323d01/build_meta.json
Process exited with code 0
Protocol
All builds must follow a simple protocol:
- Each artifact name must be unique across all projects. Define the artifact
names in a single source (hard-coded in
build_meta.py, if you like). - Each project’s buildscript defines and produces its artifacts. The internal logic of the script is irrelevant; the end result must be that the artifacts are sent to the artifact address having names conforming to the set of valid artifact names.
- All branches (even feature branches, codereviews, pull-requests, etc.) should build and upload their artifacts. (So any deploy or test system can expect the artifacts for any branch to be available.)
- The artifact address for every VCS revision is “stubbed” immediately by a commit-hook. (See metalogic)
Conclusion
The artifact system is a single, predictable “source of truth” consumable by test systems, developer workstations, and deployments. Compare the accidental approach: where QA automation, QA manual test, cloud production, on-premise patching, continuous integration, and developers each build their own artifacts using custom scripts and unshared configuration.
An artifact system, like a package system, is not purely a technical problem: it derives in part from a common understanding which may change in your organization over time. By embracing that informality, we can build a useful system with minimal effort.
The future of package management and artifact resolution demands a more sophisticated approach that eliminates the need for ecosystem-biased solutions: describe dependencies meaningfully, instead of the underspecified heuristics of traditional systems. Rich Hickey presents a way forward in “Speculation”.